



Some fascinating data points on the economics of inference:
- Nov 2021: When GPT-3 became publicly accessible, the inference cost was $60 per a million tokens
- In early 2023, running GPT-3.5 cost $20 per a million tokens (this was the price point when ChatGPT became feasible & launched!)
- Late 2023: could run Llama-2 7b at a pricepoint of $1 per a million tokens
- Mid 2024: can run Llama 3.1 8b for roughly $0.10 per a million tokens
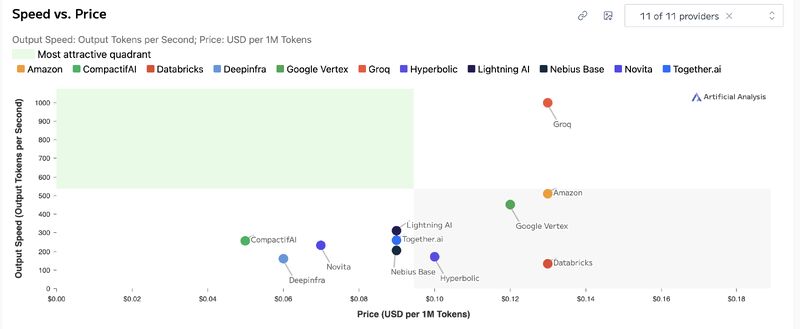
- Now: can run gpt-oss 20b for $0.05 per a million tokens (see image below)
The reduction in cost over time is simply astounding! With every reduction in inference cost or increase in inference speed (keeping model quality constant), more and more applications that were previously implausible become unlocked. This is the hallmark of a technology cycle and how markets expand! While part of this reduction in cost is due to better cost/performance of GPUs (thank you, Moore’s Law and Jensen!), there are a number of other interesting model and inference optimization techniques that help stretch out the Pareto frontier:
- Prefill Decode Disaggregation: the AI version of decoupling storage and compute. LLM inference happens in two phases - prefill (processing the input text, creating KV cache) and decode (the model generating tokens - this happens autoregressively, with each new token depending on the previously generated tokens). The compute needs for these two phases are inherently different (prefill is parallelizable and hence is compute-bound, decoding happens sequentially and hence is memory bound); inference disaggregation allows you to split these two phases into different sets of GPUs
- Pruning & Quantization: pruning involves selectively removing less significant model parameters and hence reduces size of model, making it faster and more efficient without greatly affecting performance. Quantization lowers the numerical precision of model parameters (ie going from 32-bit floating point numbers to 8-bit integers) to reduce compute overhead.
- Speculative Decoding: while the decoding step of LLM inference is sequential in nature, speculative decoding is a way to simulate its parallelization. This means using a small (cheaper) model to propose multiple next tokens, with the large model then verifying them. When the guesses are correct, inference can “skip ahead” and gain speed; when they aren't, inference falls back to the large model. Even with occasional corrections, overall latency and cost efficiency improve while preserving the same output quality.
Will be exciting to see how the trend of diminishing inference costs continues to play out over time!
(h/t Artificial Analysis for the image on gpt-oss-20B speed vs price)
👋 I’m a Researcher at Work-Bench, a Seed stage enterprise-focused VC fund based in New York City. Our sweet spot for investment at Seed correlates with building out a startup’s early go-to-market motions.

